




Computers 2025, 14(5), 188; https://doi.org/10.3390/computers14050188 - 12 May 2025
Abstract
Industry 4.0 has revolutionized the way companies manufacture, improve, and distribute their products through the use of new technologies, such as artificial intelligence, robotics, and machine learning. Autonomous Mobile Robots (AMRs), especially, have gained a lot of attention, supporting workers with daily industrial
[...] Read more.
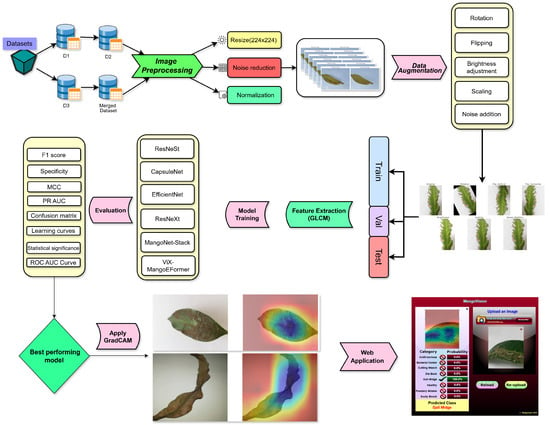
Industry 4.0 has revolutionized the way companies manufacture, improve, and distribute their products through the use of new technologies, such as artificial intelligence, robotics, and machine learning. Autonomous Mobile Robots (AMRs), especially, have gained a lot of attention, supporting workers with daily industrial tasks and boosting overall performance by delivering vital information about the status of the production line. To this end, this work presents the novel Q-CONPASS system that aims to introduce AMRs in production lines with the ultimate goal of gathering important information that can assist in production and safety control. More specifically, the Q-CONPASS system is based on an AMR equipped with a plethora of machine learning algorithms that enable the vehicle to safely navigate in a dynamic industrial environment, avoiding humans, moving machines, and stationary objects while performing important tasks. These tasks include the identification of the following: (i) missing objects during product packaging and (ii) extreme skeletal poses of workers that can lead to musculoskeletal disorders. Finally, the Q-CONPASS system was validated in a real-life environment (i.e., the lift manufacturing industry), showcasing the importance of collecting and processing data in real-time to boost productivity and improve the well-being of workers.
Full article





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}